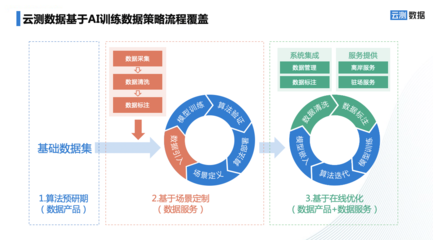
随着人工智能技术的飞速发展与应用场景的不断深化,数据作为AI模型训练与优化的重要燃料,其处理服务的需求与模式也在发生深刻变革。中国信息通信研究院(简称“信通院”)发布的《2022年人工智能白皮书》明确指出,数据服务已进入深度定制化阶段,数据处理服务正从通用化、标准化向专业化、场景化、个性化方向演进。
一、 驱动因素:需求升级与技术成熟的双重推动
- 应用场景的复杂化与多元化:人工智能已从早期的语音识别、图像识别等通用场景,深入到金融风控、医疗诊断、智能制造、自动驾驶等垂直领域。这些领域业务逻辑迥异,对数据质量、格式、处理流程、隐私安全等要求千差万别,催生了对定制化数据服务的强烈需求。
- 模型演进的精细化需求:大模型、行业模型、专属模型的兴起,对训练数据的规模、质量、多样性、标注精度提出了前所未有的高要求。例如,自动驾驶模型需要海量、精准的3D点云标注数据,而金融反欺诈模型则依赖于高度脱敏且符合业务逻辑的交易时序数据。通用数据处理方案难以满足此类精细化需求。
- 合规与安全压力日益凸显:随着《数据安全法》《个人信息保护法》等法律法规的落地,数据处理的合规性、安全性成为刚性约束。企业需要数据处理服务商能够提供符合特定行业法规(如医疗HIPAA、金融GDPR本地化要求)、特定地域政策且能实现数据“可用不可见”的定制化解决方案。
- 技术工具的赋能:自动化标注、智能数据清洗、合成数据生成、联邦学习、隐私计算等技术的发展与成熟,为高效、安全地提供深度定制化数据服务提供了技术可能。
二、 深度定制化的核心特征
信通院白皮书所定义的“深度定制化”数据处理服务,主要体现在以下几个维度:
- 需求理解的深度:服务商不再仅仅是接收指令的执行方,而是需要深入客户业务场景,理解其AI模型的目标、业务痛点、数据现状及潜在风险,共同定义数据处理的目标、标准与流程。
- 服务流程的嵌入:数据处理服务深度嵌入客户的AI研发与业务运营流程,可能涵盖从数据源咨询、采集方案设计、数据清洗与标注、质量评估、持续迭代到合规审计的全生命周期管理,提供“端到端”的解决方案。
- 技术方案的专有化:针对特定场景,开发和应用专有的数据处理工具链、标注平台、质量管理模型和算法。例如,为医疗影像开发专门的病灶标注工具与质量控制算法。
- 交付物的价值化:交付物不仅是处理后的数据集,更包括配套的标注规范、质量报告、合规证明、持续更新机制以及基于数据的分析洞察,直接服务于客户的模型效能提升与业务决策。
- 合作模式的紧密化:从传统的项目制外包,转向长期战略合作、联合研发甚至共建数据实验室等更紧密的模式,实现知识与能力的深度融合。
三、 对产业各方的启示与挑战
- 对数据服务商:提出了更高的要求。需要构建“技术+行业知识+合规能力”的三重壁垒,从劳动密集型向技术驱动型和知识服务型转型。需要组建既懂AI技术又懂垂直行业的复合型团队,并加大在垂直领域工具链和合规解决方案上的研发投入。
- 对AI应用企业:应重新评估自身的数据战略。对于核心业务数据,需考虑如何与专业服务商合作,在保障安全与主权的前提下,高效获取高质量定制数据。也需要提升内部人员的数据素养和需求定义能力,以便更好地与外部服务协同。
- 对监管与标准制定机构:深度定制化带来了新的监管挑战,例如定制化流程中的合规性如何标准化评估。信通院等机构需要推动相关技术标准、服务标准、安全标准的研制,引导产业在创新与规范之间健康发展。
四、 未来展望
数据服务进入深度定制化阶段,标志着人工智能产业正走向成熟。数据处理将更加聚焦于解决特定场景下的核心数据难题,成为AI落地不可或缺的“精工细作”环节。拥有深厚行业认知、强大技术积累和严格合规管理体系的数据处理服务商,将获得显著的竞争优势。自动化、智能化数据治理与处理平台将作为基础设施,赋能更多企业高效、低成本地获取定制化数据服务,最终推动人工智能技术在千行百业中创造更大价值。