在当今数据驱动的商业环境中,阿里巴巴作为全球领先的科技公司,其数据服务产品开发与大数据体系的建设实践,为行业提供了宝贵的参考。本文基于相关实录与干货分享,深入剖析阿里在数据处理服务领域的核心思路、产品架构与关键技术。
一、大数据体系的顶层设计与演进
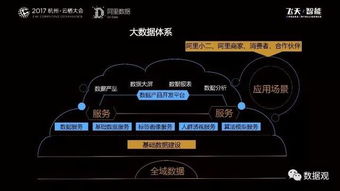
阿里的大数据体系并非一蹴而就,而是伴随着业务规模的指数级增长而持续演进的。其核心目标是构建一个统一、高效、智能的数据资产管理与服务平台。体系通常分为四层:
- 数据采集与接入层:通过阿里云DataHub、日志服务SLS等产品,实现全渠道、多源异构数据的实时与批量采集,确保数据“汇得全”。
- 数据存储与计算层:以MaxCompute(ODPS)为核心的数据仓库,结合实时计算Flink、分析型数据库AnalyticDB等,形成批流一体的计算能力,保障数据“存得下、算得快”。
- 数据管理与治理层:通过DataWorks提供一站式的数据开发、任务调度、数据质量监控与资产管理功能,实现数据的“管得好”,确保数据可信、可用。
- 数据服务与应用层:将数据资产通过API、数据市场、智能分析平台(如Quick BI)等形式,安全、高效地服务于业务端,实现数据价值的“用得上”。
二、数据处理服务产品的开发理念
阿里数据服务产品的开发始终围绕 “让数据用起来” 这一核心使命,具体体现在:
- 产品化与自助化:将复杂的大数据技术封装成易用的产品(如DataWorks、Quick BI),降低使用门槛,让业务人员也能自助完成数据查询、分析与应用。
- 场景化驱动:产品开发紧密贴合电商、物流、金融、文娱等具体业务场景,解决实际痛点,例如实时风控、个性化推荐、供应链优化等。
- 平台化与生态化:不仅服务内部,更通过阿里云向外部企业输出成熟的数据处理能力,构建开放的数据生态。
三、数据处理服务的关键技术干货
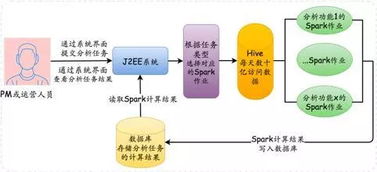
- 实时数据处理:Flink在阿里的大规模实践,实现了毫秒级延迟的实时数据管道,支撑了双11大屏、实时营销等对时效性要求极高的场景。
- 数据湖仓一体:探索将数据湖的灵活性与数据仓库的规范性相结合,在MaxCompute基础上集成OSS对象存储,实现一份数据支持多种分析范式。
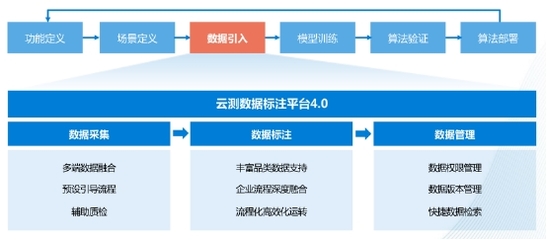
- 智能数据治理:应用机器学习技术进行元数据自动打标、数据质量异常检测、敏感数据自动识别与脱敏,大幅提升治理效率。
- 数据服务化(Data API):将数据表或查询逻辑快速封装成标准、安全的API,供前端应用直接调用,实现了数据后台与业务前端的解耦与高效协同。
四、挑战与未来展望
尽管体系成熟,阿里仍面临数据规模持续膨胀、成本控制、隐私安全合规(如GDPR、个保法)等挑战。未来趋势将聚焦于:
- 云原生数据架构:全面拥抱容器、Serverless等技术,实现更极致的弹性与资源利用率。
- 数据与AI深度融合:将AI能力更深地嵌入数据生产、管理、消费的全链路,实现从“数据智能”到“智能数据”的飞跃。
- 数据安全与可信共享:通过隐私计算等技术,在保障数据安全与隐私的前提下,促进数据要素的价值流通。
阿里数据服务产品开发及大数据体系的精髓在于,以强大的技术平台为基石,以业务价值为导向,通过产品化手段将数据处理能力民主化、普惠化。其演进历程与实战经验,为各行各业构建自身的数据能力提供了系统性的方法论与可落地的路径参考。